

715·
10 months agoRemoved by mod

Removed by mod
I arrived in China 2001.
I experienced the harshest and largest lockdown in all of history: Wuhan, January 23rd, 2020. A real lockdown, not the cosplay bullshit you experienced outside of China. (Yes, this is me saying you’ve never fucking set foot in the country.)
The rest you’re just flat-out lying about. Sorry, Sparky. Did pet killings happen? Yes. They were not the mass shit that the press you’re so obviously reciting acts like they were. Did some doors get welded? Yes. But nowhere near you and, again, nowhere near in the masses the press you’re basing your lies on made it seem like. The local salaries are garbage iff you’re a fuckwit sitting in the west applying western prices to Chinese salaries. (Which, naturally, you are, good little fuckwit liar that you are.) And you’ve changed your tune from 14 hours to 12 hours really fucking quickly there, Sparky, not to mention using the proper slang only after I gave it to you.
So yeah, you’re just a west-dwelling fuckwit lying about being here. Go toddle off in your China Watcher corners and play with the rest of the intellectual children you belong with. There’s a good boy.
Removed by mod
Not trolling. Just:
I mean it could hurt:
cube:
push {r4, r5, r6, r7, r8, r9, r10, fp}
sub sp, sp, #112
add r7, sp, #0
str r0, [r7, #92]
mov r3, sp
mov ip, r3
ldr r1, [r7, #92]
ldr r0, [r7, #92]
ldr r6, [r7, #92]
subs r3, r1, #1
str r3, [r7, #108]
mov r2, r1
movs r3, #0
mov r4, r2
mov r5, r3
mov r2, #0
mov r3, #0
lsls r3, r5, #3
orr r3, r3, r4, lsr #29
lsls r2, r4, #3
subs r3, r0, #1
str r3, [r7, #104]
mov r2, r1
movs r3, #0
str r2, [r7, #80]
str r3, [r7, #84]
mov r2, r0
movs r3, #0
str r2, [r7, #64]
str r3, [r7, #68]
ldrd r4, [r7, #80]
mov r3, r5
ldr r2, [r7, #64]
mul r2, r2, r3
ldr r3, [r7, #68]
strd r4, [r7, #80]
ldr r4, [r7, #80]
mul r3, r4, r3
add r3, r3, r2
ldr r2, [r7, #80]
ldr r4, [r7, #64]
umull r8, r9, r2, r4
add r3, r3, r9
mov r9, r3
mov r2, #0
mov r3, #0
lsl r3, r9, #3
orr r3, r3, r8, lsr #29
lsl r2, r8, #3
subs r3, r6, #1
str r3, [r7, #100]
mov r2, r1
movs r3, #0
str r2, [r7, #32]
str r3, [r7, #36]
mov r2, r0
movs r3, #0
str r2, [r7, #72]
str r3, [r7, #76]
ldrd r4, [r7, #32]
mov r3, r5
ldrd r8, [r7, #72]
mov r2, r8
mul r2, r2, r3
strd r8, [r7, #72]
ldr r3, [r7, #76]
mov r8, r4
mov r9, r5
mov r4, r8
mul r3, r4, r3
add r3, r3, r2
mov r2, r8
ldr r4, [r7, #72]
umull r10, fp, r2, r4
add r3, r3, fp
mov fp, r3
mov r2, r6
movs r3, #0
str r2, [r7, #24]
str r3, [r7, #28]
ldrd r4, [r7, #24]
mov r3, r4
mul r2, r3, fp
mov r3, r5
mul r3, r10, r3
add r3, r3, r2
mov r2, r4
umull r4, r2, r10, r2
str r2, [r7, #60]
mov r2, r4
str r2, [r7, #56]
ldr r2, [r7, #60]
add r3, r3, r2
str r3, [r7, #60]
mov r2, #0
mov r3, #0
ldrd r8, [r7, #56]
mov r4, r9
lsls r3, r4, #3
mov r4, r8
orr r3, r3, r4, lsr #29
mov r4, r8
lsls r2, r4, #3
mov r2, r1
movs r3, #0
str r2, [r7, #16]
str r3, [r7, #20]
mov r2, r0
movs r3, #0
str r2, [r7, #8]
str r3, [r7, #12]
ldrd r8, [r7, #16]
mov r3, r9
ldrd r10, [r7, #8]
mov r2, r10
mul r2, r2, r3
mov r3, fp
mov r4, r8
mul r3, r4, r3
add r3, r3, r2
mov r2, r8
mov r4, r10
umull r4, r2, r2, r4
str r2, [r7, #52]
mov r2, r4
str r2, [r7, #48]
ldr r2, [r7, #52]
add r3, r3, r2
str r3, [r7, #52]
mov r2, r6
movs r3, #0
str r2, [r7]
str r3, [r7, #4]
ldrd r8, [r7, #48]
mov r3, r9
ldrd r10, [r7]
mov r2, r10
mul r2, r2, r3
mov r3, fp
mov r4, r8
mul r3, r4, r3
add r3, r3, r2
mov r2, r8
mov r4, r10
umull r4, r2, r2, r4
str r2, [r7, #44]
mov r2, r4
str r2, [r7, #40]
ldr r2, [r7, #44]
add r3, r3, r2
str r3, [r7, #44]
mov r2, #0
mov r3, #0
ldrd r8, [r7, #40]
mov r4, r9
lsls r3, r4, #3
mov r4, r8
orr r3, r3, r4, lsr #29
mov r4, r8
lsls r2, r4, #3
mov r3, r1
mov r2, r0
mul r3, r2, r3
mov r2, r6
mul r3, r2, r3
adds r3, r3, #7
lsrs r3, r3, #3
lsls r3, r3, #3
sub sp, sp, r3
mov r3, sp
str r3, [r7, #96]
mov r3, r1
mov r2, r0
mul r3, r2, r3
mov r2, r6
mul r3, r2, r3
mov sp, ip
mov r0, r3
adds r7, r7, #112
mov sp, r7
pop {r4, r5, r6, r7, r8, r9, r10, fp}
bx lr
Multiplication hurts? 😲
cube:
mul r3, r0, r0
mul r0, r3, r0
bx lr

No. This is like asking if a 6502 microprocessor can run a 6809’s code because they’re both 8-bit micros.
The family of instruction sets under the RISC-V banner is completely different from the family of instruction sets under the ARM banner. I’ll compile this program for RISC-V and ARM and show you the compiler outputs for an example:
#include
int main(int argc, char** argv)
{
printf("Hello, world!");
}
First ARM (a fairly generic ARM32 processor core’s output):
.LC0:
.ascii "Hello, world!\000"
main:
push {r7, lr}
sub sp, sp, #8
add r7, sp, #0
str r0, [r7, #4]
str r1, [r7]
movw r0, #:lower16:.LC0
movt r0, #:upper16:.LC0
bl printf
movs r3, #0
mov r0, r3
adds r7, r7, #8
mov sp, r7
pop {r7, pc}
Now RISC-V (again a fairly convention 32-bit RISC-V core):
.LC0:
.string "Hello, world!"
main:
addi sp,sp,-32
sw ra,28(sp)
sw s0,24(sp)
addi s0,sp,32
sw a0,-20(s0)
sw a1,-24(s0)
lui a5,%hi(.LC0)
addi a0,a5,%lo(.LC0)
call printf
li a5,0
mv a0,a5
lw ra,28(sp)
lw s0,24(sp)
addi sp,sp,32
jr ra
Comparing the two you’re going to note several very major differences. One of the biggest and easiest to spot, however, is how ARM pushes r7 and lr onto the stack at the beginning, but pops r7 and pc at the end. This is because lr contains the “return address” (it’s a bit more complicated than that, but close enough for jazz) on entry and pc is the “program counter” which is where the processor will get its next instruction from. By popping what was the lr value into pc you’ve effectively done a transfer of control to the return address without an explicit branch.
RISC-V, conversely, uses ra (their equivalent of lr) pushed onto the stack (note how each value is pushed manually, not part of a combined instruction), then popped back from the stack and an explicit jr branch instruction is used to set the next instruction to be executed. So even ignoring the different names of instructions (which could just be different naming conventions for the same thing), the very way the two systems operate is very different.
So while ARM and RISC-V are both RISC processors, they are not even similar to each other in operations beyond both following the RISC philosophy of instruction set design.
This makes absolutely no sense in my country.
This makes absolutely no sense in any country. The whole “Sovereign Citizens” movement (and its offshoots and influences) is a steaming hot pile of garbage that’s being cooked by an underlying tire fire. It’s what happens when sociopaths interact with each other in ways that feed and fan the flames of their disorder.

Oh, sorry, did any of your pearls fall? Thanks for your precious “engagement”.
I guess it’s scary for some people to participate in even a conversation about something new with an open mind without being condescending.
Irony, thy name is … well, just check the user name. It’s all you need.
The author, w/o explicitly mentioning it anywhere, is explicitly talking about distributed systems where you’ve got plenty of resources, stable network connectivity and a log/trace ingestion solution (like Sumo or Datadog) alongside your setup.
That is the very core of my objection. He hasn’t identified the warrants for his argument, meaning his argument is literally gibberish to people working from a different set of warrants. Dudebro here could learn a thing or two from Toulmin.
This is a problem endemic to techbros writing about tech. They assume, quite incorrectly, that the entire world is just clones of themselves perhaps a little bit behind on the learning curve. (It never occurs, naturally, that others might be ahead of them on the learning curve or *gasp!* that there may be more than one curve! That would be silly!)
So they write without establishing their warrants. (Hell, they often write without bothering to define their terms, because “trace” means the same thing in all forms of computer technology, amirite?!) They write as if they have The Answer instead of merely a possible answer in a limited set of circumstance (which they fail to identify). And they write as if they’re on the top of the learning heap instead of, as is statistically far more likely, somewhere in the middle.
Which makes it funny when he sings the praises of a tracing library that, when I investigated it briefly, made me choke with laughter at just how painfully ineffective it is compared to tools I’ve used in the past; specifically Erlang’s tracing tools. The library he’s text-wanking to is pitifully weak compared to what comes out of the box in an Erlang environment. You have to manually insert tracing calls (error-prone, tedious, obfuscatory) for example. Whatever you don’t decide to trace in advance can’t be traced. Whereas Erlang’s tracing system (and, presumably Ruby-on-BEAM’s, a.k.a. Elixir) lets you make ad hoc tracing calls on live systems as they’re executing. This means you can trace a live system as it’s fucking up without having to be a precognitive psychic when coding, leaving the costs of tracing at 0 until such a time as you genuinely need them.
So he doesn’t identify his warrants, he writes as if he has the One True Answer, he assumes all programming forms use the same jargon in the same way, and he acts as if he’s the guru sharing his wisdom when he’s actually way behind the curve on the very tech he’s pitching.
He is a, in a word, programmer.
My own thoughts.
Instead of defining the difference between logging and tracing, the author spams the screen with pages’ worth of examples of why logging is bad, then jumps into tracing by immediately referencing code that uses a specific tracing library (OpenTelemetry Tracer) without at any point explaining what that code is actually doing to someone who is not familiar with it already. To me this smacks of preaching to the choir since if you’re already familiar with this tool, you’re likely already a) familiar with what “tracing” is compared to “logging”, and b) probably a tracing advocate to begin with. If you want to persuade an undecided or unfamiliar audience, confusing them and/or making assumptions about what they know or don’t know is … suboptimal.
If you’re going to screen dump your code in your rant, FUCKING COMMENT IT YOU GIT! I don’t want to have to read through 100 lines of code in an unfamiliar language written to an unfamiliar architecture to find the three (!) lines that are actually on the fucking topic!
If you’re going to show changes in your code, put before/after snapshots side by side so I don’t have to go scrolling back to the uncommented hundred-line blob to see what changed. It’s not that hard. Using his own damned example from “Step 1”:
// BEFORE
func PrepareContainer(ctx context.Context, container ContainerContext, locales []string, dryRun bool, allLocalesRequired bool) (*StatusResult, error) {
logger.Info(`Filling home page template`)
// AFTER
var tr = otel.Tracer("container_api")
func PrepareContainer(ctx context.Context, container ContainerContext, locales []string, dryRun bool, allLocalesRequired bool) (*StatusResult, error) {
ctx, span := tr.Start(ctx, "prepare_container")
defer span.End()
(And while you’re at it, how 'bout explaining the fucking code you wrote? How hard is it to add a line explaining what that defer span.End() nonsense is? Remember, you’re trying to sell people on the need for tracing. If they already know what you’re talking about you’re preaching to the choir, son.)
Of course in “The Result” he talks about the diff between the two functions … but doesn’t actually provide that diff. Instead he provides another hundred-line blob kept far away from the original so you have to bounce back and forth between them to spot the differences. Side-by-side diffs are a thing and there’s plenty of tools that make supplying them trivial. Maybe the author should think about using them.
Points for having a good sense of humour about it!
Step one: learn the name of the language?
Sloppiness is rarely contained in one narrow area. If programmers are so sloppy they’re using up 1.5-2GB to do literally nothing, then they’re sloppy in how they do pretty much everything.
My very first computer had all my friends exceedingly jealous. I had 208KB of RAM see. (No, that’s not a typo. KB.) I could run four simultaneous users, each user having 48KB of RAM with a staggering 16KB available for the operating system. I had available spreadsheet and word processing applications, as well as, naturally, development applications. (I also had a secret weapon that drove my friends crazy: while they were swapping around their floppy disks holding 160KB of data each, I had two of those … and I had a 5MB hard disk!
I compare those days to now and I have to laugh. My current computer (which is considered pretty weak by modern standards since I don’t game so I don’t give a fuck about GPUs and ten billion cores and clock rates in the Petahertz range) is almost four orders of magnitude faster than that first computer at the CPU level. I have six orders of magnitude more disk space and the disks are at least 3 orders of magnitude faster (possibly more: I don’t have the stats for the old drive on hand.) I have five orders of magnitude more memory and it, again, is probably 3 orders of magnitude or more faster.
Yet …
I don’t feel anywhere from 3 to 6 orders of magnitude more productive. Indeed I’d be surprised if I went about an order of magnitude better in terms of productivity with this (barely) modern machine than I had with my first machine. Things look prettier (by far!) I’ll admit that, but in terms of actually getting anything done, these thousands, to millions of times more resources are basically 100% wasted. And they’re wasted precisely because every time we increase our ability to do something in a computer by a factor of 10, sloppy- and lazy-assed programmers increase the resources they use to get things done by a factor of 11.
And it shows.
That old computer? Slow as it was, it booted from nothing to full, multi-user functionality in 10 seconds. 10 seconds after turning the power on, I could have up to four users running their software (or in my case one user with four screens) without a care in the world. Loading the word processor or spreadsheet was practically instantaneous. One, maybe two seconds. It didn’t register as a wait. I just timed loading LibreOffice Writer on this modern system that runs four orders of magnitude faster. Six seconds, give or take. Which not even a slow-loading program! (Web browsers take significantly longer….)
And you know what problem I never once faced on that old computer running under a ten-thousandth (!) the speed? Typing faster than the system could keep up while displaying text. Yet as I type this I’m consistently typing one or two characters faster than the web browser can update plain text in a box. More than a ten thousand times faster!
So yes, yes it matters. When a system made likely before you were even born is running circles around a modern system in key pieces of functionality (albeit looking far, far, far prettier while doing it!), there’s something that’s going horribly wrong in software. And shit like VS Code is almost the Platonic Form of what’s wrong with software today: bloated, slow, and so overpacked with features it has no elegance in functionality or implementation.
But hey, if you want to waste 2GB of RAM to load a 12KB text file, more power to you! I’ll stick with a system that only wastes 30MB of RAM to do the same, and runs faster, and looks cleaner, and is easier to extend. (And since its total code, including the C code and the Lua extensions, is something you can peruse and understand out of the box in a weekend, it’s also less buggy than VS Code: that’s the other cost of bloat, after all. Bugs.)
The thing that made me go to it was its syntax highlighting engine. I tend to use languages that aren’t well-supported by common tools (like VSCode), and Textadept makes it simple. REALLY simple.
As an example, I supplied the lexer for Prolog and Logtalk. Prolog is a large language and very fractious: there’s MANY dialects with some rather sizable differences. The lexer I supplied for Prolog is ~350 lines long and supplies full, detailed syntax highlighting for three (very) different dialects of Prolog: ISO, GNU, and SWI. (I’ll be adding Trealla in my Copious Free Time™ Real Soon Now™. On average it will be about another 100 lines for any decently-sized dialect.) I’ve never encountered another syntax highlighting system that can do what I did in Textadept in anywhere near that small a number of lines. If they can do them at all (most can’t cope with the dialect issue), they do them in ways that are painful and error-prone.
And then there’s Logtalk.
Logtalk is a cap language. It’s a declarative OOP language that uses various Prologs as a back-end. Which is to say there is, in effect, a dialect of Logtalk for each dialect of Prolog. So given that Logtalk is a superset of Prolog you’d expect the lexer file for it to be as big or bigger, right?
Nope.
64 lines.
The Logtalk support—a superset of Prolog—adds only 64 lines. And it’s not like it copies the Prolog support and adds 64 lines for a total of ~420 in the file. The Logtalk lexer file is 64 lines long. Because Textadept lexers can inherit from other lexers and extend them, OOP-style. This has several implications.
In addition to this inheritance mechanism, take a look at this beautiful bit of bounty from the HTML lexer:
-- Embedded JavaScript ().
local js = lexer.load('javascript')
local script_tag = word_match('script', true)
local js_start_rule = #('<' * script_tag * ('>' + P(function(input, index)
if input:find('^%s+type%s*=%s*(["\'])text/javascript%1', index) then return true end
end))) * lex.embed_start_tag
local js_end_rule = #('') * lex.embed_end_tag
lex:embed(js, js_start_rule, js_end_rule)
-- Embedded CoffeeScript ().
local cs = lexer.load('coffeescript')
script_tag = word_match('script', true)
local cs_start_rule = #('<' * script_tag * P(function(input, index)
if input:find('^[^>]+type%s*=%s*(["\'])text/coffeescript%1', index) then return true end
end)) * lex.embed_start_tag
local cs_end_rule = #('') * lex.embed_end_tag
lex:embed(cs, cs_start_rule, cs_end_rule)
You can embed other languages into a top level language. The code you read here will look for the tags that start JavaScript or CoffeeScript and, upon finding them, will process the Java/CoffeeScript with their own independent lexer before coming back to the HTML lexer. (Similar code is in the HTML lexer for CSS.)
Similarly, for those unfortunate enough to have to work with JSP, the JSP lexer will invoke the Java lexer for embedded Java code, with similar benefits for when Java changes. Even more fun: the JSP lexer just extends the HTML lexer with that embedding. So when you edit JSP code at any given point you can be in the HTML lexer, the CSS lexer, the JavaScript lexer, the CoffeeScript lexer, or the Java Lexer and you don’t know or care why or when. It’s completely seamless, and any changes to any of the individual lexers are automatically reflected in any of the lexers that inherit from or embed another lexer.
Out of the box, Textadept comes with lexer support for ~150 languages of which ~25 use inheritance and/or embedding giving it some pretty spiffy flexibility. And yet this is only ~15,000 LOC total, or an average of 100 lines of code per language. Again, nothing else I’ve seen comes close (and that doesn’t even address how much EASIER writing a Textadept lexer is than any other system I’ve ever seen).
Doing nothing from the problem domain. I mean I could make a “hello world” program that occupies 16TB of RAM because it does weird crap before printing the message.
The problem domain is text editing. An idle text editor (not even displaying text!) is “doing nothing”. The fact it was programmed by someone to occupy multiple GB of space to do that nothing is bad programming.
I use Textadept over any of the named ones, including VS Code. (I use the vi subset of Vim for remote access to machines I haven’t yet installed Textadept on.)
Why?
I have a moral objection to … Well let me show you:
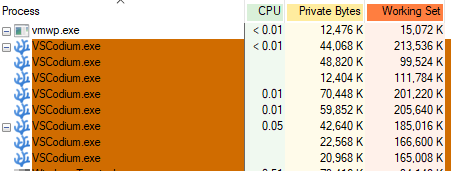

One of those is VSCode (well, VSCodium, which is VSCode without Microsoft’s spyware installed), and the other is Textadept. One of those is occupying almost 30MB of memory to do nothing. The other is occupying about 1.5-2GB of memory … to do nothing. In both cases there are no files open and no compilers being run, etc. I find this kind of intense wastefulness a sign of garbage software and I try not to use garbage software. (Unfortunately I’m required to use garbage Windows 10 at work. 😒)
Oh, and Textadapt has both a GUI version (and not the shit GUI that Emacs provides in its GUI version!) and a console version, allowing me to quickly get it running even on remote machines I have to use. VSCode/Codium … not so much. I’d have to run it with remote X and … that is painful when doing long-distance stuff.
Seriously, my dude. Touch grass.
Yes. Keep thinking that way. You’ll find ZERO normal people agreeing with you, mind. You might need to go out, touch grass, talk to people who aren’t permanently wired.

Removed by mod